
High-Speed Networks, Data Centers, Artificial Intelligence
Everyone's talking about GPUs. Compute power, chip shortages, hyperscale campuses springing up overnight — that's where the AI infrastructure conversation has lived for the past couple of years.
But there's a quieter shift happening underneath all of it, and it's just as important: the network that connects everything together.
As AI workloads grow, the real question isn't just "how much compute can we pack into one building?" It's "how fast can we move data between buildings, cities, and continents?" Fiber connectivity and data center interconnect (DCI) are quickly becoming the piece of infrastructure that determines how far and how fast AI can actually scale.
Why a Single Data Center Isn't Enough Anymore
For a while, AI infrastructure growth was about going bigger inside one facility — packing in denser GPU clusters and building out the internal fiber needed to keep all that compute talking to itself.
That approach is hitting a wall. Power capacity is limited. Cooling gets harder as density increases. Land near major metros is scarce and expensive. Operators can't just keep stacking more inside a single site.
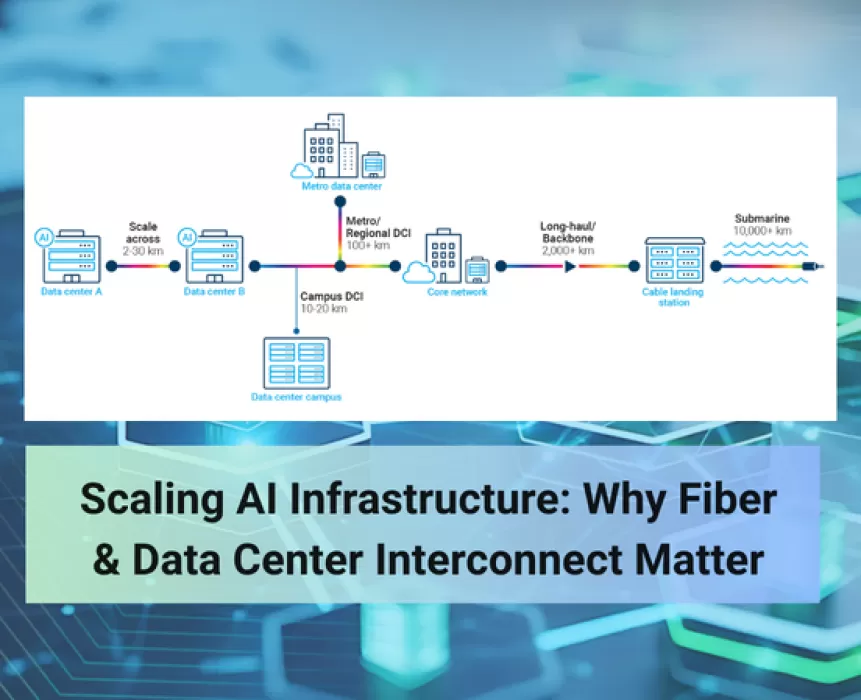
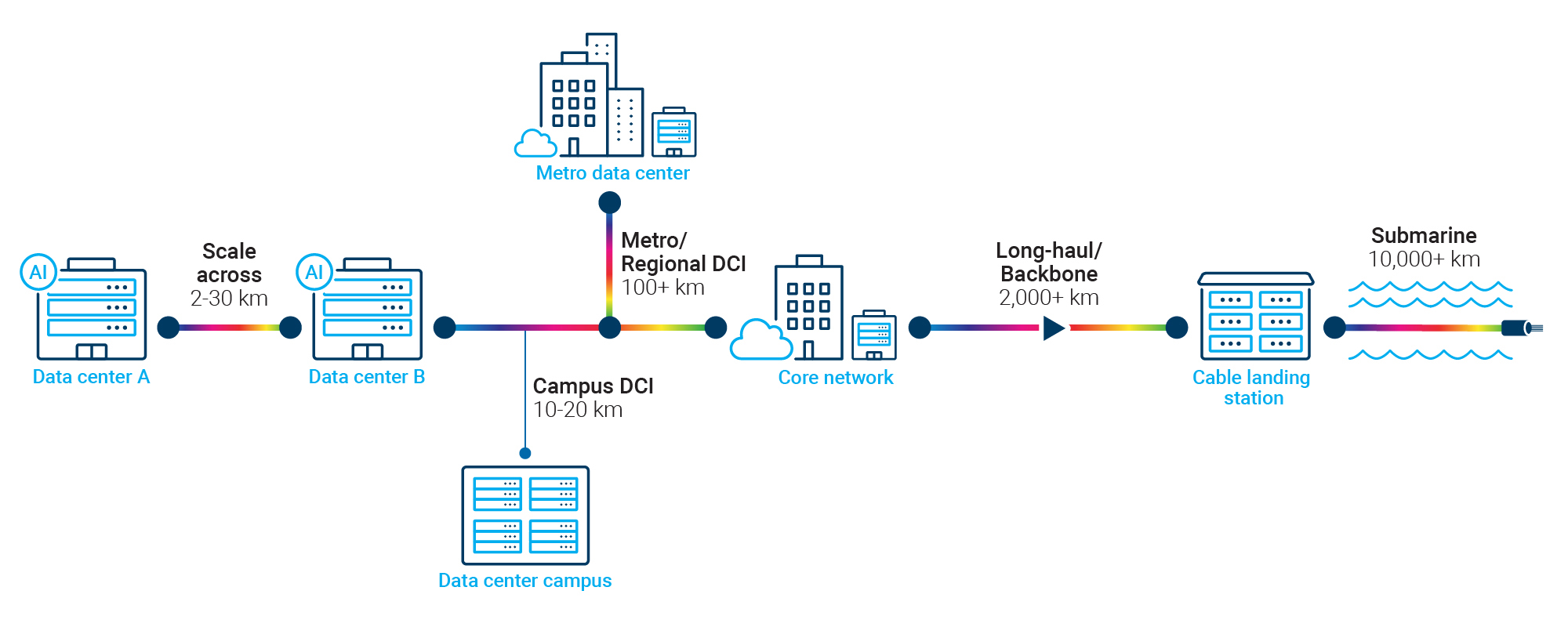
So the strategy is shifting from scaling up to scaling across — spreading compute over multiple facilities in different locations instead of cramming it all into one. That shift puts data center interconnect front and center. DCI used to be treated as a backup layer, something you built for redundancy. Now it's core infrastructure, essential for training AI models, running inference, and operating distributed cloud environments.
The Network Layer Powering AI Growth
High-capacity fiber links between facilities let workloads span multiple sites, sharing compute resources and shuttling enormous datasets back and forth in something close to real time.
The underlying transport technology is evolving fast to keep up. Networks that were running 100G not long ago have jumped to 400G and 800G, and the industry roadmap already points toward 1.6T and beyond. That pace isn't arbitrary — it's a direct response to how quickly AI traffic is growing and how badly cloud and hyperscale operators need efficient ways to link their environments together.
The numbers back this up too. The global DCI market is already sitting in the mid-teens of billions of dollars, and forecasts point to continued double-digit growth as AI and hyperscale architecture keep pushing demand for more interconnection capacity.
The Middle Layer Nobody Talks About: Regional Fiber
Between short metro connections and massive long-haul backbone routes sits an often-overlooked layer: regional fiber. These routes are what actually connect distributed data center clusters within a given geography, and they're becoming a bigger deal as operators look for more capacity, path diversity, and routing options.
Interestingly, some of the new supply is coming from unexpected places. Utility companies, rail operators, and transportation authorities are opening up their rights-of-way to lease or deploy dark fiber, which is speeding up how quickly new regional routes can go live. Regional fiber isn't a "nice to have" anymore — it's becoming a strategic piece of how distributed AI infrastructure actually gets built.
The Hidden Challenge: Deploying at This Scale Isn't Simple
Demand for fiber is climbing fast, but building it out is getting more complicated, not less. When a project scales from tens of fiber strands to hundreds or even thousands, the old way of doing things — manual coordination, paper trails, inconsistent field processes — starts to break down fast.
Small mistakes compound quickly at this scale: a mislabeled fiber, a manually entered test value that's slightly off, a report that doesn't match the next one. These aren't dramatic failures on their own, but they add up to delays, rework, and lost time.
That's pushing operators toward automation across the board — parallelized testing, better fiber identification and polarity checks, and more standardized processes in the field. Deployment is also getting more digitized, giving field crews clear, structured guidance on what to test, how to test it, and how to log results consistently. The payoff is fewer errors and faster time to service.
Testing Can't Be an Afterthought Anymore
Testing used to be the last box to check before a network went live — certify it, sign off, move on. That's changing. Operators are now weaving testing into every stage of deployment instead of saving it for the end, because it's a lot cheaper to catch a problem early than to find it after the network is already in production.
New fiber types like hollow core and multicore fiber, combined with how fast optical transport speeds are changing, mean testing methods have to keep evolving too. Automation and remote testing are a big part of how operators are keeping up — they allow for higher throughput, less manual work, and round-the-clock validation on large deployments.
What It Takes to Build for the Long Haul
Looking ahead, operators are dealing with real pressure: limited supply, workforce shortages, and networks that just keep getting more complex. Getting through that isn't just about building infrastructure and certifying it once. It takes ongoing visibility into network health, automation woven through every stage of deployment, and an operational strategy built with future upgrades already in mind.
The companies that come out ahead will be the ones that treat quality, testing, and automation as things that actually enable scale — not obstacles that slow deployment down.
Fiber isn't just plumbing anymore. In the AI era, it's the foundation that decides how fast innovation can actually move.